
BASE
DE DATOS NO RELACIONAL
¿Qué
son las bases de datos NoSQL?
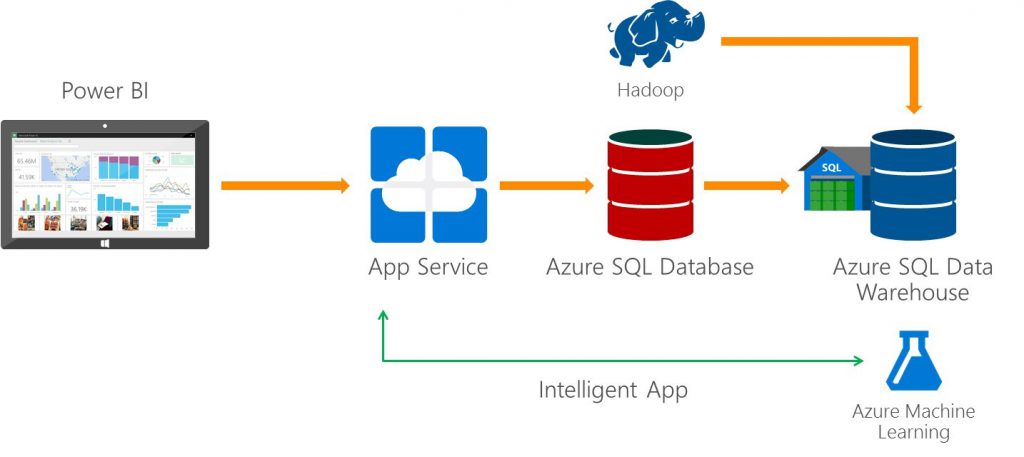
¿Cómo
funciona una base de datos NoSQL (no relacionales)?
Las bases de datos NoSQL
utilizan una variedad de modelos de datos para acceder y administrar datos,
como documentos, gráficos, clave-valor, en-memoria y búsqueda. Estos tipos de
bases de datos están optimizados específicamente para aplicaciones que
requieren grandes volúmenes de datos, baja latencia y modelos de datos
flexibles, lo que se logra mediante la flexibilización de algunas de las
restricciones de coherencia de datos en otras bases de datos.
En una base de datos relacional, un
registro de libros a menudo se enmascara (o "normaliza") y se
almacena en tablas separadas, y las relaciones se definen mediante
restricciones de claves primarias y externas. En este ejemplo, la tabla Libros
tiene las columnas ISBN, Título del libro y Número de edición, la tabla Autores
tiene las columnas IDAutor y Nombre de autor y, finalmente, la tabla Autor-ISBN
tiene las columnas IDAutor e ISBN. El modelo relacional está diseñado para
permitir que la base de datos aplique la integridad referencial entre tablas en
la base de datos, normalizada para reducir la redundancia y, generalmente, está
optimizada para el almacenamiento.
En una base de datos NoSQL, el registro de
un libro generalmente se almacena como un documento JSON. Para cada libro, el
elemento, ISBN, Título del libro, Número de edición, Nombre autor y IDAutor se
almacenan como atributos en un solo documento. En este modelo, los datos están
optimizados para un desarrollo intuitivo y escalabilidad horizontal.
¿Por
qué debería usar una base de datos NoSQL?
Las bases de datos NoSQL se
adaptan perfectamente a muchas aplicaciones modernas, como dispositivos
móviles, web y juegos, que requieren bases de datos flexibles, escalables, de
alto rendimiento y altamente funcionales para proporcionar excelentes
experiencias de usuario.
Flexibilidad: las bases de datos NoSQL
generalmente ofrecen esquemas flexibles que permiten un desarrollo más rápido y
más iterativo. El modelo de datos flexible hace que las bases de datos NoSQL
sean ideales para datos semiestructurados y no estructurados.Escalabilidad: las bases de datos NoSQL generalmente están diseñadas para escalar usando clústeres distribuidos de hardware en lugar de escalar añadiendo servidores caros y sólidos. Algunos proveedores de la nube manejan estas operaciones fuera del alcance, como un servicio completamente administrado.
Alto rendimiento: la base de datos NoSQL está optimizada para modelos de datos específicos (como documentos, clave-valor y gráficos) y patrones de acceso que permiten un mayor rendimiento que el intento de lograr una funcionalidad similar con bases de datos relacionales.
Altamente funcional: las bases de datos NoSQL proporcionan API altamente funcionales y tipos de datos que están diseñados específicamente para cada uno de sus respectivos modelos de datos.
Tipos
de bases de datos NoSQL

SQL
(relacional) en comparación con NoSQL (no relacional)
Durante décadas, el modelo
de datos predominante utilizado para el desarrollo de aplicaciones era el
modelo de datos relacional empleado por bases de datos relacionales como
Oracle, DB2, SQL Server, MySQL y PostgreSQL. No fue sino hasta mediados y
finales de la década del 2000 que otros modelos de datos comenzaron a adoptarse
y aumentó su uso significativamente. Para diferenciar y categorizar estas
nuevas clases de bases de datos y modelos de datos, se acuñó el término
"NoSQL". Con frecuencia, los términos "NoSQL" y "no
relacional" se usan indistintamente.
Cargas
de trabajo óptimas
Las bases de datos relacionales están diseñadas para
aplicaciones de procesamiento de transacciones online (OLTP) altamente
coherentes y transaccionales, y son buenas para el procesamiento analítico
online (OLAP). Las bases de
datos clave-valor, documentos, gráficos y en memoria de NoSQL están diseñadas
para OLTP para una serie de patrones de acceso a datos que incluyen
aplicaciones de baja latencia. Las bases de datos de búsqueda NoSQL están
diseñadas para hacer análisis sobre datos semiestructurados.
Modelo
de datos
El modelo relacional
normaliza los datos en tablas conformadas por filas y columnas. Un esquema
define estrictamente las tablas, las filas, las columnas, los índices, las
relaciones entre las tablas y otros elementos de las bases de datos. La base de
datos impone la integridad referencial en las relaciones entre tablas.
Las bases de datos NoSQL proporcionan una variedad de
modelos de datos, que incluyen documentos, gráficos, clave-valor, en-memoria y
búsqueda.
Propiedades
ACID
Las bases de datos
relacionales ofrecen propiedades de atomicidad, coherencia, aislamiento y
durabilidad (ACID):
- La atomicidad requiere que una transacción se ejecute por completo o no se ejecute en absoluto.
- La coherencia requiere que una vez confirmada una transacción, los datos deban acoplarse al esquema de la base de datos.
- El aislamiento requiere que las transacciones simultáneas se ejecuten por separado.
- La durabilidad requiere la capacidad de recuperarse de un error inesperado del sistema o de un corte de energía y volver al último estado conocido.
Las bases de datos NoSQL a menudo hacen concesiones al
flexibilizar algunas de las propiedades ACID de las bases de datos relacionales
para un modelo de datos más flexible que puede escalar horizontalmente. Esto
hace que las bases de datos NoSQL sean una excelente opción para casos de uso
de baja latencia y alto rendimiento que necesitan escalar horizontalmente más
allá de las limitaciones de una sola instancia.
Rendimiento Normalmente, el rendimiento depende
del subsistema de disco. Se necesita la optimización de consultas, índices y
estructura de tabla para lograr el máximo rendimiento. El rendimiento es, por lo general, depende del tamaño del clúster
de hardware subyacente, la latencia de red y la aplicación que efectúa la
llamada.
Escalado Las bases de datos relacionales
generalmente escalan en forma ascendente las capacidades de computación del
hardware o la ampliación mediante la adición de réplicas para cargas de trabajo
de solo lectura. Las bases de
datos NoSQL normalmente se pueden particionar porque los patrones de acceso de
valores clave son escalables mediante el uso de arquitectura distribuida para
aumentar el rendimiento que proporciona un rendimiento constante a una escala
casi ilimitada.
API Solicita almacenar y recuperar datos que están comunicados
mediante consultas que se ajustan a un lenguaje de consulta estructurado (SQL).
Estas consultas son analizadas y ejecutadas por la base de datos relacional.Las API basadas en objetos permiten a
los desarrolladores almacenar y recuperar fácilmente estructuras de datos en
memoria. Las claves de partición permiten que las aplicaciones busquen pares de
clave-valor, conjuntos de columnas o documentos semiestructurados que contengan
atributos y objetos de aplicación serializados.
 Es un sistema de base de
datos NoSQL orientado a documentos de código abierto.En lugar de guardar los
datos en tablas, tal y como se hace en las bases de datos relacionales, MongoDB
guarda estructuras de datos BSON (una especificación similar a JSON) con un
esquema dinámico, haciendo que la integración de los datos en ciertas
aplicaciones sea más fácil y rápida.
Es un sistema de base de
datos NoSQL orientado a documentos de código abierto.En lugar de guardar los
datos en tablas, tal y como se hace en las bases de datos relacionales, MongoDB
guarda estructuras de datos BSON (una especificación similar a JSON) con un
esquema dinámico, haciendo que la integración de los datos en ciertas
aplicaciones sea más fácil y rápida.
C
C++
C# / .NET
Erlang
Haskell
J#
Java
JavaScript
Lisp
Node.js
Perl
PHP
Python
Ruby
Delphi
Scala
mongostat24
MONGODB
MongoDB es una base de datos
adecuada para su uso en producción y con múltiples funcionalidades. Esta base
de datos se utiliza mucho en la industria,1 contando con implantaciones en
empresas como MTV Network,2 Craiglist,3 BCI o Foursquare.
El código binario está
disponible para los sistemas operativos Windows, GNU/Linux, OS X y Solaris.
Características
principales
Consultas ad hoc
MongoDB soporta la búsqueda
por campos, consultas de rangos y expresiones regulares. Las consultas pueden
devolver un campo específico del documento pero también puede ser una función
definida por el usuario para su mejor ocupacion.JavaScript
Indexación
Cualquier campo en un
documento de MongoDB puede ser indexado, al igual que es posible hacer índices
secundarios. El concepto de índices en MongoDB es similar al empleado en base
de datos relacionales..
Replicación
Balanceo de carga
MongoDB puede escalar de
forma horizontal usando el concepto de [shard.14 El desarrollador elige una
clave de sharding, la cual determina cómo serán distribuidos los datos de una
colección. Los datos son divididos en rangos (basado en la clave de sharding) y
distribuidos a través de múltiples shard. Cada shard puede ser una réplica set.
MongoDB tiene la capacidad de ejecutarse en múltiple servidores, balanceando la
carga y/o replicando los datos para poder mantener el sistema funcionando en
caso que exista un fallo de hardware. La configuración automática es fácil de
implementar bajo MongoDB y se pueden agregar nuevas servidores a MongoDB con el
sistema de base de datos funcionando.
Almacenamiento de archivos
MongoDB puede ser utilizado
como un sistema de archivos, aprovechando la capacidad de MongoDB para el
balanceo de carga y la replicación de datos en múltiples servidores. Esta
funcionalidad, llamada GridFS15 e incluida en la distribución oficial,
implementa sobre los drivers, no sobre el servidor16, una serie de funciones y
métodos para manipular archivos y contenido. En un sistema con múltiple
servidores, los archivos pueden ser distribuidos y replicados entre los mismos
de forma transparente, creando así un sistema eficiente tolerante a fallos y
con balanceo de carga.
Agregación
MongoDB proporciona un
framework de agregación que permite realizar operaciones similares al
"GROUP BY" de SQL. El framework de agregación está construido como un
pipeline en el que los datos van pasando a través de diferentes etapas en los
cuales estos datos son modificados, agregados, filtrados y formateados hasta
obtener el resultado deseado. Todo este procesado es capaz de utilizar índices
si existieran y se produce en memoria. Asimismo, MongoDB proporciona una
función MapReduce que puede ser utilizada para el procesamiento por lotes de
datos y operaciones de agregación.
Ejecución de JavaScript del
lado del servidor
MongoDB tiene la capacidad
de realizar consultas utilizando JavaScript, haciendo que estas sean enviadas
directamente a la base de datos para ser ejecutadas.
Fragmentación
(sharding)
Si estás desarrollando un
servicio que se va haciendo popular o los niveles de acceso a base de datos son
cada vez más altos, empezarás a notar que tu base de datos está siendo atacada
por un tráfico creciente y tu servidor esté sufriendo por los altos niveles de
stress y te podrías ver en la necesidad de actualizar tu infraestructura para
soportar la demanda.
Aquí entra en juego el
sharding, es el modo en el que hacemos nuestra base de datos escalable. En
lugar de tener una colección en una base de datos, la pondríamos en varias
bases de datos distribuidas, de modo que a la hora de consultar los datos de
dicha colección, los recuperemos como si de una única base de datos se tratase.
Mongo se encargará de averiguar de manera transparente en qué base de datos se
encuentran los datos.
Casos
de uso
La base de datos MongoDB es
adecuada para los siguientes usos:20
Almacenamiento y registro de
eventos
Sistemas de manejo de
documentos y contenido
Comercio electrónico
Juegos
Sistemas con alto volumen de
lecturas
Aplicaciones móviles
Almacén de datos operacional
de sitios web
Almacenamiento de
comentarios
Votaciones
Registro de usuarios
Perfiles de usuarios
Sesiones de datos
Proyectos que utilizan
metodologías de desarrollo iterativo o ágiles
Manejo de estadísticas en
tiempo real
MongoDB es utilizado para
uno o varios de estos casos por varias empresas.
Manipulación
de datos: colecciones y documentos
MongoDB guarda la estructura
de los datos en documentos BSON con un esquema dinámico, lo que implica que no
existe un esquema predefinido. Los elementos de los datos se denominan
documentos y se guardan en colecciones. Una colección puede tener un número
indeterminado de documentos. Comparando con una base de datos relacional, se
puede decir que las colecciones son como tablas y los documentos son registros
en la tabla. La diferencia es que en una base de datos relacional cada registro
en una tabla tiene la misma cantidad de campos, mientras que en MongoDB cada
documento en una colección puede tener diferentes campos. En un documento, se
pueden agregar, eliminar, modificar o renombrar nuevos campos en cualquier
momento,22 ya que no hay un esquema predefinido.
Lenguajes
de programación soportados
C++
C# / .NET
Erlang
Haskell
J#
Java
JavaScript
Lisp
Node.js
Perl
PHP
Python
Ruby
Delphi
Scala
Instrumentos
de MongoDB
Los siguientes comandos
pueden ser instalados para el manejo y la administración del sistema de base de
datos:
mongo23
Shell interactivo que
permite a los desarrolladores y administradores ver, insertar, eliminar y
actualizar datos en su base de datos. Este también permite entre otras
funciones la replicación de datos, configuración de sharding, apagar los
servidores, ejecutar JavaScript y todos los comandos que se puedan realizar.
mongostat24
Instrumento de línea de
comandos que muestra en resumen una lista de estadísticas de una instancia de
MongoDB en ejecución. Esto te permite visualizar cuantas inserciones, actualizaciones,
eliminaciones, consultas y comandos se han ejecutado, pero también cuanta
memoria está utilizando y cuanto tiempo ha estado cerrada la base de datos.
mongotop25
Instrumento de línea de
comandos que provee un método para dar seguimiento a la cantidad de tiempo que
dura una lectura o escritura de datos en una instancia. También provee
estadísticas en el nivel de cada colección.
mongosniff26
Instrumento de línea de
comandos que provee un sniffing en la base de datos haciendo un sniffing en el
tráfico de la red que va desde y hacia MongoDB.
mongoimport27/mongoexport28
Instrumento de línea de
comandos que facilita la importación exportación de contenido desde JSON, CSV o
TSV. También tiene el potencial de importar o exportar hacia otros formatos.
mongodump29/mongorestore30
Instrumento de línea de
comandos para la creación de una imagen binaria del contenido de la base de
datos. Estos comandos son utilizados para la estrategia de copias de seguridad
en MongoDB.
 Es un sistema de gestión de
bases de datos derivado de MySQL con licencia GPL . Es desarrollado por Michael
(Monty) Widenius, la fundación MariaDB y la comunidad de desarrolladores de
software libre. Introduce dos motores de almacenamiento nuevos, uno llamado.
Tiene una alta compatibilidad con MySQL ya que posee las mismas órdenes,
interfaces, API y bibliotecas, siendo su objetivo poder cambiar un servidor por
otro directamente.
Es un sistema de gestión de
bases de datos derivado de MySQL con licencia GPL . Es desarrollado por Michael
(Monty) Widenius, la fundación MariaDB y la comunidad de desarrolladores de
software libre. Introduce dos motores de almacenamiento nuevos, uno llamado.
Tiene una alta compatibilidad con MySQL ya que posee las mismas órdenes,
interfaces, API y bibliotecas, siendo su objetivo poder cambiar un servidor por
otro directamente.

MariaDB
Es un sistema de gestión de
bases de datos derivado de MySQL con licencia GPL . Es desarrollado por Michael
(Monty) Widenius, la fundación MariaDB y la comunidad de desarrolladores de
software libre. Introduce dos motores de almacenamiento nuevos, uno llamado.
Tiene una alta compatibilidad con MySQL ya que posee las mismas órdenes,
interfaces, API y bibliotecas, siendo su objetivo poder cambiar un servidor por
otro directamente.
Este SGBD surge a raíz de la
compra de Sun Microsystems por parte de Oracle. MariaDB es una bifurcación
directa de MySQL que asegura la existencia de una versión de este producto con
licencia GPL. Widenius decidió crear esta variante porque estaba convencido de
que el único interés de Oracle en MySQL era reducir la competencia que MySQL
suponía para el mayor proveedor de bases de datos relacionales del mundo, que
es Oracle.
Software
de terceros
Hay bastantes paquetes
privativos y libres de terceros diseñados para MySQL que también están
disponibles para integrarse con MariaDB. Algunos ejemplos son:
- DBEdit: Una aplicación de administración libre para MariaDB y otras bases de datos.
- dbForge Studio for MySQL: Aplicación propietaria de gestión de bases de datos MySQL compatible con MariaDB.
- Navicat: Una serie de aplicaciones propietarias de gestión de bases de datos para Windows, Mac OS X y Linux.
- SQLyog: Aplicación propietaria de gestión de bases de datos MySQL compatible con MariaDB para Windows y Linux.
- HeidiSQL: Un cliente de fuente abierta y libre para MySQL, 100% compatible con MariaDB, incluido con el paquete MSI para Windows de MariaDB desde la versión 5.2.7.56
- phpMyAdmin: Una aplicación web de administración libre para MySQL compatible con MariaDB.
Versiones
La versión de desarrollo de
MariaDB es la 10.0.7 Está construida sobre la versión 5.5, con algunas
características de MySQL 5.6 y otras prestaciones nuevas no encontradas en
ninguna otra versión anterior.
Diferencias
con MySQL
Mecanismos de almacenamiento
Además de los mecanismos de
almacenamiento estándar MyISAM, Blackhole, CSV, Memory y Archive, también se
incluyen en la versión fuente y binaria de MariaDB los siguientes:
Aria (alternativa a MyISAM
resistente a caídas)
XtraDB (reemplazo directo de
InnoDB)
PBXT (en MariaDB 5.1, 5.2 y
5.3. Deshabilitada en 5.5)
FederatedX (reemplazo
directo de Federated)
OQGRAPH — nuevo en 5.2
SphinxSE — nuevo en 5.2
IBMDB2I. Eliminada por
Oracle de MySQL 5.1.55 pero se incluye en el código de MariaDB hasta la versión
5.5.
Cassandra, en MariaDB 10.0
(otros mecanismos no-sql se incluirán en MariaDB)
Sequence, aparecido con
MariaDB 10.0.3
Facilidad
de uso
Proporciona estadísticas de
índices y tabla, para lo que añade nuevas tablas en INFORMATION_SCHEMA y nuevas
opciones a los comandos FLUSH y SHOW para identificar la causa en la carga del
SGBD.
Los comandos ALTER TABLE y
LOAD DATA INFILE dejan de ser opacos e informan del progreso.
La precisión para tipo de
datos TIME, DATETIME, y TIMESTAMP ampliada al microsegundo.
Introducidas características
estilo NoSQL, como HandlerSocket que proporciona acceso directo a tablas InnoDB
saltándose la capa SQL.
Columnas dinámicas, que
proporcionan al usuario columnas virtuales en las tablas.
Prestaciones
El optimizador de MariaDB
-que se encuentra en el núcleo de cualquier SGBD- funciona claramente más
rápido con cargas complejas.
En la replicación se han
introducido sustanciosas mejoras, por ejemplo el “group commit for the binary
log” que acelera la replicación hasta el doble.
Eliminación de tablas. El
acceso a tablas a través de views acelera el acceso.
Testeo
Más juegos de test en la
distribución.
Parches para los tests.
Distintas combinaciones de
configuración y sistema operativo para los tests.
Eliminación de tests
innecesarios, como "no testar la característica X si no la he incluido en
mi ejecutable".
Menos
errores y alertas
Los juegos de testeo han
permitido reducir los errores sin introducir nuevos.
Las alertas de compilación
están relacionadas, y los desarrolladores las han intentado reducir.
¿Cuando
usar MariaDB?
MariaDB se puede usar en
cualquier lugar donde antes se usaba MySQL. Como se trata de un sistema
compatible, todo software que antes usase MySQL es capaz de seguir funcionando
igualmente con MariaDB. Por tanto, se puede usar MariaDB en cualquier proyecto
de nueva creación, así como intercambiar MySQL por MariaDB en prácticamente
todos los proyectos que puedan estar ya en producción. El paso es inmediato y
no requiere cambiar nada en el código, simplemente instalar MariaDB y volver a
crear las bases de datos y tablas en el nuevo sistema.
¿Por
qué usar MariaDB?
MariaDB ha seguido el
desarrollo del sistema gestor MySQL, implementando diversas mejoras y nuevas
funcionalidades. Las mejoras muchas veces afectan directamente al rendimiento o
permiten optimizar mejor las bases de datos, por lo que usar MariaDB siempre
será una opción interesante. Además, nos garantizamos que vamos a disfrutar de
un software con mayor crecimiento y progresión que el propio MySQL.
Entre las novedades que ya
han sido implementadas en MariaDB, podemos destacar:
Nuevos motores de
almacenamiento como Aria, que permite sustituir a MyISAM con algunas mejoras, y
XtraDB, que viene a evolucionar InnoDB.
Nuevas características
disponibles, relacionadas directamente con las características disponibles en
bases de datos NoSQL.
Nueva gestión de conexiones
con la base de datos, que permite multiplicar el número de accesos de manera
concurrente.
Nuevos motores de
funcionamiento en cluster, como Galera, que nos permiten interesantes
posibilidades de cara a la adopción Cloud.
Además, al tratarse de una
comunidad muy dinámica y abierta a los desarrolladores, MariaDB garantiza la
aparición más rápida de parches, que puedan solucionar eventuales problemas de
seguridad.
MariaDB se puede usar desde
la mayoría de sistemas de administración existentes para MySQL, como PhpMyAdmin
o HeidiSQL, y es compatible con aplicaciones tan populares como WordPress,
Drupal, etc. La compatibilidad es tal que muchas veces el uso de MariaDB en
lugar de MySQL es transparente para desarrolladores o administradores de
sistemas. Prueba de ello es que, para arrancar los servicios de MariaDB, o para
hacer login en el sistema gestor por medio de línea de comandos, se usan los
mismos mecanismos ya conocidos en MySQL.

DynamoDB es un servicio de base de datos noSQL ofrecido por Amazon como parte de Amazon Web Services. DynamoDB expone un modelo de datos similar y deriva su nombre de Dynamo (un sistema de almacenamiento interno utilizado inicialmente para su propio sitio web), pero tiene una implementación subyacente diferente.
 Aplicaciones
web sin servidor
Aplicaciones
web sin servidor
AMAZON DYNAMODB
DynamoDB es un servicio de base de datos noSQL ofrecido por Amazon como parte de Amazon Web Services. DynamoDB expone un modelo de datos similar y deriva su nombre de Dynamo (un sistema de almacenamiento interno utilizado inicialmente para su propio sitio web), pero tiene una implementación subyacente diferente.
Dynamo tenía un diseño multimaestro que requería que el cliente resolviera
conflictos de versiones y DynamoDB usa replicación síncrona en múltiples
centros de datos para una alta durabilidad y disponibilidad. DynamoDB fue
anunciado por Amazon CTO Werner Vogels el 18 de enero de 2012.
Descripción general
DynamoDB
difiere de otros servicios de Amazon al permitir a los desarrolladores comprar
un servicio basado en el rendimiento, en lugar de almacenamiento. Si tiene Auto
Scaling habilitado, la base de datos escalará automáticamente. Además, los
administradores pueden solicitar cambios de rendimiento y DynamoDB extenderá los
datos y el tráfico en una serie de servidores mediante unidades de estado
sólido, lo que permite un rendimiento predecible. Ofrece integración con Hadoop
a través de Elastic MapReduce.
Solicitudes
Métricas
relacionadas con la creación de un Índice Secundario Global (Global Secondary
Index)
Estas
métricas se pueden rastrear utilizando la consola de administración de AWS,
utilizando la interfaz de línea de comandos de AWS o una herramienta de
supervisión que se integra con Amazon CloudWatch.
Beneficios
Rendimiento
a escala
DynamoDB
admite algunas de las aplicaciones de escala más grandes del mundo y
proporciona tiempos de respuesta en milisegundos de un solo dígito a cualquier
escala. Puede crear aplicaciones con capacidad de almacenamiento y
procesamiento prácticamente ilimitada. Las tablas globales de DynamoDB replican
sus datos en varias regiones de AWS para darle acceso rápido y local a los
datos para sus aplicaciones distribuidas globalmente. Para casos de uso que
requieren un acceso aún más rápido con latencia de microsegundos, DynamoDB
Accelerator (DAX) proporciona caché en memoria completamente administrada.
Sin servidor
Con
DynamoDB, no hay servidores que aprovisionar, parchear o administrar, y no hay
software que instalar, mantener o utilizar. DynamoDB aumenta o reduce
automáticamente las tablas para ajustar la capacidad y mantener el rendimiento.
La disponibilidad y la tolerancia a errores están integradas, por lo que no es
necesario tener en cuenta estas capacidades a la hora de diseñar sus aplicaciones.
DynamoDB proporciona los modos de capacidad bajo demanda y de capacidad
aprovisionada para que pueda optimizar los costos mediante la especificación de
la capacidad por carga de trabajo o el pago de los recursos que consume.
Listo para el uso empresarial
DynamoDB
admite las transacciones ACID para que pueda crear aplicaciones de vital
importancia para el negocio a escala. DynamoDB cifra todos los datos de forma
predeterminada y proporciona un control de acceso e identidad detallado en
todas las tablas.
Puede crear copias de seguridad completas de cientos de
terabytes de datos al instante sin que el rendimiento afecte a sus tablas, y
recuperarlas en cualquier momento en los 35 días anteriores sin tiempo de
inactividad. DynamoDB también cuenta con el respaldo de un acuerdo de nivel de
servicio para garantizar la disponibilidad.
Aplicaciones
Aplicaciones
web sin servidor
Cree
aplicaciones web eficientes que ajusten su escala automáticamente. No necesita
mantener servidores y las aplicaciones cuentan con alta disponibilidad
automatizada.
Back-ends
móviles
Use
DynamoDB y AWS AppSync para crear aplicaciones web y móviles interactivas con
actualizaciones en tiempo real, acceso a datos sin conexión y sincronización de
datos con resolución de conflictos integrada.
Microservicios
Cree
microservicios flexibles y reutilizables mediante el uso de DynamoDB como un
almacén de datos sin servidor para lograr un rendimiento estable y ágil.
 Originalmente conocido como
Membase, es un proyecto de código abierto, un paquete de software distribuido
(del inglés arquitecturas shared-nothing) multi-modelo orientado a base de
datos documental y que está optimizado para aplicaciones interactivas.Estas aplicaciones pueden
servir a muchos usuarios al mismo tiempo mediante la creación, almacenamiento,
recuperación, agregación, manipulación y presentación de datos. Para soportar
este tipo de necesidades, Couchbase Server está diseñado para proporcionar
acceso a documentos de valor-clave (del inglés key - value documents) o
documentos JSON de fácil escala, con baja latencia y alto rendimiento
sostenido. Está diseñado para ser agrupado a partir de una sola máquina a gran
escala que abarca muchas máquinas (clúster).
Originalmente conocido como
Membase, es un proyecto de código abierto, un paquete de software distribuido
(del inglés arquitecturas shared-nothing) multi-modelo orientado a base de
datos documental y que está optimizado para aplicaciones interactivas.Estas aplicaciones pueden
servir a muchos usuarios al mismo tiempo mediante la creación, almacenamiento,
recuperación, agregación, manipulación y presentación de datos. Para soportar
este tipo de necesidades, Couchbase Server está diseñado para proporcionar
acceso a documentos de valor-clave (del inglés key - value documents) o
documentos JSON de fácil escala, con baja latencia y alto rendimiento
sostenido. Está diseñado para ser agrupado a partir de una sola máquina a gran
escala que abarca muchas máquinas (clúster).
 Couchbase Server es una
versión empaquetada del software de código abierto de CouchBase y está
disponible en una edición de la comunidad sin recientes correcciones de errores
con licencia Apache 2.0.9 y una edición para uso comercial.10 Couchbase
Server está disponible para los sistemas operativos Ubuntu, Debian, Red Hat,
SUSE, Oracle Linux, Microsoft Windows y Mac OS X.
Couchbase Server es una
versión empaquetada del software de código abierto de CouchBase y está
disponible en una edición de la comunidad sin recientes correcciones de errores
con licencia Apache 2.0.9 y una edición para uso comercial.10 Couchbase
Server está disponible para los sistemas operativos Ubuntu, Debian, Red Hat,
SUSE, Oracle Linux, Microsoft Windows y Mac OS X.
COUCHBASE
Originalmente conocido como
Membase, es un proyecto de código abierto, un paquete de software distribuido
(del inglés arquitecturas shared-nothing) multi-modelo orientado a base de
datos documental y que está optimizado para aplicaciones interactivas.Estas aplicaciones pueden
servir a muchos usuarios al mismo tiempo mediante la creación, almacenamiento,
recuperación, agregación, manipulación y presentación de datos. Para soportar
este tipo de necesidades, Couchbase Server está diseñado para proporcionar
acceso a documentos de valor-clave (del inglés key - value documents) o
documentos JSON de fácil escala, con baja latencia y alto rendimiento
sostenido. Está diseñado para ser agrupado a partir de una sola máquina a gran
escala que abarca muchas máquinas (clúster).
El Servidor de Couchbase
proporciona compatibilidad con el protocolo de cliente memcached, agregando
persistencia de disco, replicación de datos, reconfiguración del clúster en
vivo, reequilibrio y multiusuario con partición de datos.
Detalles
Membase fue desarrollado por
varios dirigentes del proyecto memcached, que habían fundado la compañía,
NorthScale, para desarrollar un almacén de datos claves-valor con la
simplicidad, velocidad y escalabilidad de memcached, pero que también
proporcionara el almacenamiento, la persistencia y las capacidades de consulta
de una base de datos. El código fuente membase original fue aportado por
NorthScale, y por los co-patrocinadores de Zynga y Naver (entonces conocido
como NHN) a un nuevo proyecto sobre membase.org en junio de 2010.
Los fundadores del proyecto
Membase y Membase, Inc. anunciaron una fusión con CouchOne (una empresa con
muchas de las principales figuras detrás de CouchDB) con una mezcla de proyecto
asociado. La empresa fusionada fue llamada Couchbase, Inc. En enero de 2012,
Couchbase lanzó Couchbase Server 1.8.
Arquitectura
Cada nodo de Couchbase
consta de un servicio de datos, servicio de índice, servicio de consulta y
componente de administrador de clúster. A partir de la versión 4.0, los tres
servicios se pueden distribuir para ejecutarse en nodos separados del clúster
si es necesario. En términos del teorema CAP de Eric Brewer, Couchbase es
normalmente un sistema de tipo CP lo que significa que proporciona consistencia
de datos y tolerancia de partición, o puede ser configurado como un sistema de
punto de acceso (AP) con varios clústeres.
Administrador
de clústeres
El administrador del clúster
supervisa la configuración y el comportamiento de todos los servidores de un
clúster de Couchbase. Configura y supervisa el comportamiento entre nodos, así
como la gestión de flujos de replicación y operaciones de reequilibrio. También
proporciona funciones de agregación y de consenso métricas en el clúster y una
interfaz de gestión de clústeres REST. El gestor de clúster utiliza el lenguaje
de programación Erlang y Open Telecom Platform.
Replicación
y conmutación por error
La replicación (informática)
dentro de los nodos de un clúster se puede controlar con varios parámetros. En
diciembre de 2012, la replicación también fue soportada entre los diferentes
centros de datos.
Gestor
de datos
El gestor de datos almacena
y reintenta documentos en respuesta a las operaciones de datos de las
aplicaciones. De forma asíncrona escribe datos en el disco después de reconocer
al cliente. En la versión 1.7 y posteriores, las aplicaciones pueden asegurar
opcionalmente que los datos se escriban en más de un servidor o en disco antes
de reconocer una escritura al cliente.
Los parámetros definen las
edades de los elementos que afectan cuando los datos se mantienen y cómo se
gestiona la memoria máxima y la migración desde la memoria principal al disco.
Soporta conjuntos de trabajo mayores que una cuota de memoria por
"nodo" o "cubo". Los sistemas externos pueden suscribirse a
los flujos de datos filtrados, apoyando, por ejemplo, indexación de búsqueda
con texto completo, análisis de datos o archivo.
Formato
de datos
Un documento es la unidad
más básica de manipulación de datos en Couchbase Server. Los documentos se
almacenan en formato JSON, sin esquemas predefinidos.
Memoria
caché de objetos gestionados
Couchbase Server incluye una
caché integrada multi-hilo de objetos, que implementa las API compatibles con
memcached tales como get, set, delete, append, prepend, etc.
Motor
de almacenamiento
Couchbase Server tiene un
diseño de almacenamiento tail-append que es inmune a la corrupción de datos,
asesinos OOM o pérdida repentina del poder. Los datos se escriben en el archivo
de datos de forma append-only, lo que permite a Couchbase hacer principalmente
escrituras secuenciales para actualizar y proporcionar patrones de acceso
optimizados de E/S en el disco.
Rendimiento
Una referencia de
rendimiento realizado por Altoros en 2012, compara Couchbase Server con otras
tecnologías. Cisco Systems publicó un punto de referencia que mide la latencia
y el rendimiento de Couchbase Server con una carga de trabajo mixta en 2012.
Licenciamiento
y soporte
Couchbase Server es una
versión empaquetada del software de código abierto de CouchBase y está
disponible en una edición de la comunidad sin recientes correcciones de errores
con licencia Apache 2.0.9 y una edición para uso comercial.10 Couchbase
Server está disponible para los sistemas operativos Ubuntu, Debian, Red Hat,
SUSE, Oracle Linux, Microsoft Windows y Mac OS X.
Couchbase ha apoyado
herramientas de desarrollo de software de los lenguajes de programación .Net,
PHP, Ruby, Python, C, Node.js, Java, and Go.
N1QL
El lenguaje de consulta N1QL
(del inglés non-first normal form query language), se utiliza para la búsqueda
de datos en el servidor. Se anunció en marzo de 2015, como "SQL para
documentos".
El modelo de datos N1QL es
N1NF (del inglés non-first normal form) con soporte para atributos anidados y
normalización orientada a dominio. El modelo de datos N1QL también es un
superconjunto apropiado y una generalización del modelo relacional.
No hay comentarios:
Publicar un comentario